YOLOv7 vs YOLOv6
-
YOLOv7 Objece Detection
Real-time Model at its Best
-
YOLOv7 Instance Segmentation
Real-time Model at its Best
-
YOLOv7 Post Estimation
Real-time Model at its Best
Real-time Model at its Best
Real-time Model at its Best
Real-time Model at its Best
博主:)
歡迎大家跟我一起討論電腦視覺相關主題唷~
本文將先針對「電腦視覺」中常用的「影像分類(Image Classification)」、「物件偵測(Object Detection)」「實例分割(Instance Segmentation)」及「人體骨架(Human Skeleton)」等幾大領域作簡單的「任務定義」
YOLO
2021 年 Swin-Transformer 霸榜各大電腦視覺任務,Transformer 是為序列建模和轉換任務而設計的, 因為它關注數據的長期依賴性,其在語言領域的巨大成功促使學者研究它對電腦視覺的適應性,本文重點探討將 Transformer 從 NLP 轉移到 CV 的策略。 2021 年以前各大電腦視覺任務主要被 CNN 所統治,CNN 架構已經通過更大的規模,更廣泛的連接,以及更複雜的卷積形式而逐漸壯大。
Transformer
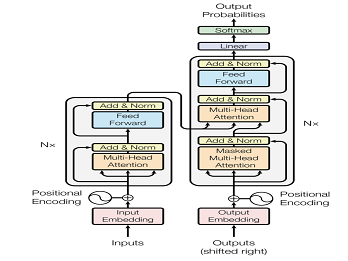
RNN 無法丟到 GPU 進行平行化運算,導致運算時間會被拉得非常長。 而 CNN 非常適合平行化運算,所以就有學者提出 CNN 搭配自注意力機制取代 RNN , 它可以平行化運算,而且每一個輸出向量,都看過整個輸入序列。 更重要的是:「我們可以把所有 RNN 架構做得到的事,都換成以 Self-Attention 來達成。」…

2020 年,將純粹的 Transformer 引入 CV 領域的論文引起了各路好手的廣泛關注,Vision-Transformer 的一系列研究工作大多數是對標準 Transformer 進行了增強。Vision-Transformer 並不是第一個嘗試將 Transformer 引入 CV 領域的論文,在 Transformer 霸榜 NLP 領域後,許多論文就開始嘗試將 Transformer 應用到 CV 領域,但發現了一個痛點,就是計算量非常驚人! …

2021 年微軟研究人員發表了 Swin-Transformer,這可以說是原始 Vision-Transformer 後最令人興奮的研究之一。Swin-Transformer 不光是應用範圍廣,效果更是炸裂,看名字就知道是個基於 Transformer 模型,在視覺任務中取得了非常先進的 Performance,Swin-Transformer 目前被廣泛作為模型的骨幹(Backbone)。…
李沐團隊針對自監督學習(Self-Supervised Learning, SSL)的分支對比學習(Contrastive Learning),在電腦視覺領域的發展進行了一個非常好的總結,這幾年真的卷出了非常多的 Trick。 2019 年 Facebook AI 提出的 MoCo 橫空出世,掀起了自監督學習在電腦視覺領域的熱潮,接續 Google Brain 相繼提出 SimCLR,自監督學習呈現出百花齊放,百家爭鳴空前繁榮的景象。但是繁榮的背後,自監督學習經歷了漫長的迭代和發展過程。
Self-Supervised Learning

本綜述針對 2018 年起自監督學習在計算機視覺領域的發展歷程,共分為四階段。這邊只是把最有關連性的論文給串接在一起,談論一下它們的相似及不同之處,不會精讀每篇論文,只會花 3~5 分鐘講一下它的研究動機、方法以及它的貢獻,將代表性的工作做一個總結。…

2018 年開始,自監督學習開始火了起來,當時被提出來的方法、模型架構(Model)、代理任務(Pretext Task)、目標函數(Loss)五花八門,皆未有統一的論述, 可以說此階段是一個百花齊放的時代。本章節將會介紹 InstDist 以及 InvaSpread 兩篇最具代表意義的論文。…
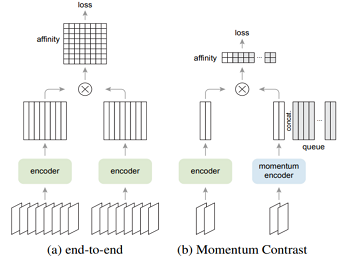
2019 年兩大科技巨頭 Facebook AI 和 Google-Brain 相繼提出 MOCO 系列、SimCLR 系列 ,這個階段發展非常迅速,每個月都在刷新 ImageNet 上的成績。本章節將介紹 SimCLR v1、MOCO v2、SimCLR v1、 SimCLR v2、SwAV 這些具代表意義的論文。…
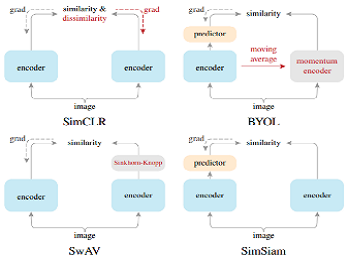
2020 年英國知名 AI 公司 DeepMind 提出 BYOL ,引入了一個新的思維-不用負樣本也能學習,此階段主要講到 BYOL 這個方法以及它後續的改進,最後 Facebook AI 出手,把所有方法都歸納總結融入到了 Simsiam 這個框架之中。…
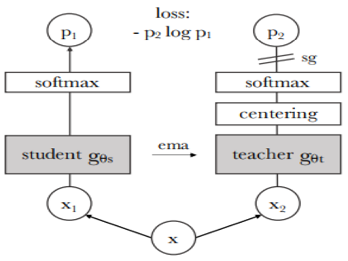
2021年 Facebook AI 提出了 MoCo v3,引入了 Vi-T。此時的 Vi-T 非常火熱,一半的視覺研究者都投入到了它的懷抱,所以對於自監督學習來說,大家接下來都是用 Vi-T 去實現。本章節將會介紹 MOVO v3 、DINO 這兩篇最具代表意義的論文。…
Copyright © 2018 - All Rights Reserved - Domain Name
Template by OS Templates